Unsupervised Learning with Linear Algebra: Two Ways
Kate Kenny
CS 0451
In this post, we will be exploring unsupervised learning through two examples. We will be working with Singular Value Decomposition (SVD) to do image compression and with Spectral Community Detection to deal with clusters of data. As a result, this blog post is broken into those two sections to explore each topic seperately.
Singular Value Decompostion
The SVD of a matrix \(\mathbf{A} \in \mathbb{R}^{mxn}\) is as follows.
\(\mathbf{A = UDV}^T\)
where \(\mathbf{D}\) is a diagonal matrix and the matrices \(\mathbf{U}\) and \(\mathbf{V}\) are orthogonal matrices. The entries of \(\mathbf{D}\), \(\sigma_i\), give some measure of how large \(\textbf{A}\) is. We can approximate the matrix \(\textbf{A}\) using a representation that only considers the first \(k\) columns of \(\textbf{U}\), \(k\) values in \(\textbf{D}\) and the first \(k\) rows of \(\textbf{V}\).
In this post, we are going to use SVD to construct approximations of a greyscale image using different values of \(k\).
Choosing an image
First, let’s choose an RGB image and convert it to greyscale. I am selecting a picture of a Nova Scotia Duck Tolling Retriever.
Now, our image is a very large matrix. So we can implement SVD to approximate the picture!
We are going to write a few methods in this post included svd_reconstruct() which will reconstruct an image using a given value \(k\) and svd_experiment() which will reconstruct an image for a variety of \(k\) values and determine the percentage of the original image’s storage needed for each reconstruction. Additionally, we will need to write some methods to view and compare our images and reconstructions.
Let’s implement the svd_reconstruct() function that allows us to specify \(k\) and perform SVD reconstruction on an image using that value.
from matplotlib import pyplot as pltimport numpy as npdef svd_reconstruct(img, k): #reconstructs img from SVD using k values A = img U, sigma, V = np.linalg.svd(A)#construct diagonal matrix D whose entries are entires of sigma D = np.zeros_like(A,dtype=float) # matrix of zeros of same shape as A D[:min(A.shape),:min(A.shape)] = np.diag(sigma)#index first k rows/entries/columns of U, D, and V respectively U_ = U[:,:k] D_ = D[:k, :k] V_ = V[:k, :] A_ = U_ @ D_ @ V_return A_
Now that we have our reconstruct function, let’s try it for \(k=5\) on the image selected above.
This is not a great approximation, but we can start to see our image taking shape even with a \(k\) value as low as 5. So now let’s implement our experimentation function and see how different \(k\) values perform when reconstructing our image.
It is striking how low the percentage of storage needed to store these images is. Part of the reason for this could be the image we are using in our experiment, which has a shape of (900, 744) and consequently requires a large number of pixels for storage itself. This really shows the utility of our reconstructed images as there is no difference to the naked high with 100 components yet the storage demands are vastly different.
Spectral Community Detection
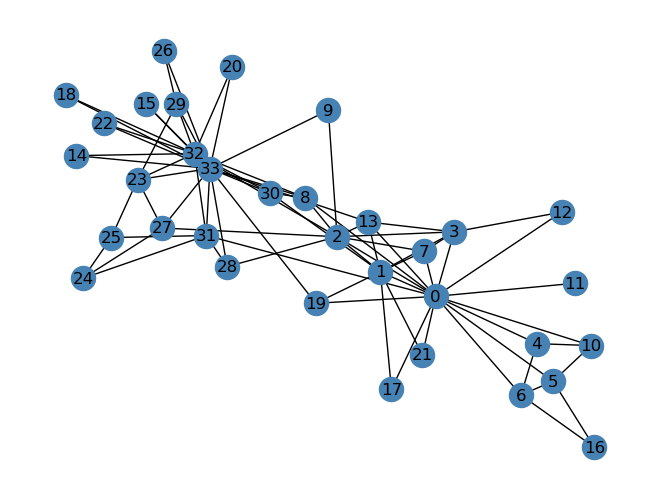
Next, we are going to explore unsupervised learning in the context of Laplacian spectral clustering. Specifically, we will be looking at a graph that represents a social network, specifically a karate club. Below is the network.
clubs = nx.get_node_attributes(G, "club")nx.draw(G, layout, with_labels=True, node_color = ["orange"if clubs[i] =="Officer"else"steelblue"for i in G.nodes()], edgecolors ="black"# confusingly, this is the color of node borders, not of edges )
Spectral clustering is a method to define clustering as good when we don’t “cut” too many edges. “Cutting” edges in this instance is labelling two conencted nodes with different labels.
To implement this, we want to find a vector \(z\) that minimizes the normalized cut objective function \(f(\textbf{z}, \textbf{A})\) which is defined below. Let \(\textbf{A}\) be the adjacency matrix of a graph \(G\).
\[
f(z, A) = \text{cut}({A}, {z})\left(\frac{1}{\text{vol}_{0}(A, z)} + \frac{1}{\text{vol}_{1}(A, z)}\right)\]
where \[
\text{vol}_{j}({A}{z}) = \sum_{i = 1}^n \sum_{i' = 1}^n 1*[{z_i = j}] a_{ii'}
\] In other words, \(\text{vol}_{j}({A}{z})\) is the number of edges that have one node in cluster \(j\).
Although we cannot solve for \(z\) directly, we can approximate \(z\) using an eigenvector of the Laplacian matrix, \(L = (D)^{-1}(D - A)\) where \[
\textbf{D} = \left[\begin{matrix} \sum_{i = 1}^n a_{i1} & & & \\
& \sum_{i = 1}^n a_{i2} & & \\
& & \ddots & \\
& & & \sum_{i = 1}^n a_{in}
\end{matrix}\right]\;.
\]\(z\) can be approximated by the eigenvector associated with the second smallest eigenvalue of \(L\). In the implementation below, we will find \(L\) and the associated eigenvector which can approximate \(z\) and predict the clustering of the Karate club.
def spectral_clustering(G): #define adjacency matrix A A = nx.adjacency_matrix(G).toarray()#construct diagonal matrix D whose entries are sum of respective row in A diag = np.sum(A, axis =1) D = np.diag(diag)#calculate L L = (np.linalg.inv(D))@(D - A)#compute eigenvalues and corresponding eigenvectors eigs, eig_vecs = np.linalg.eig(L)#delete min eigenvalue and corresponding eigenvector eigs2 = np.delete(eigs, np.argmin(eigs, axis=None), 0) eig_vecs2 = np.delete(eig_vecs, np.argmin(eigs), 1) z = eig_vecs2[:, np.argmin(eigs2)]return z#create labels based on z and plot graph
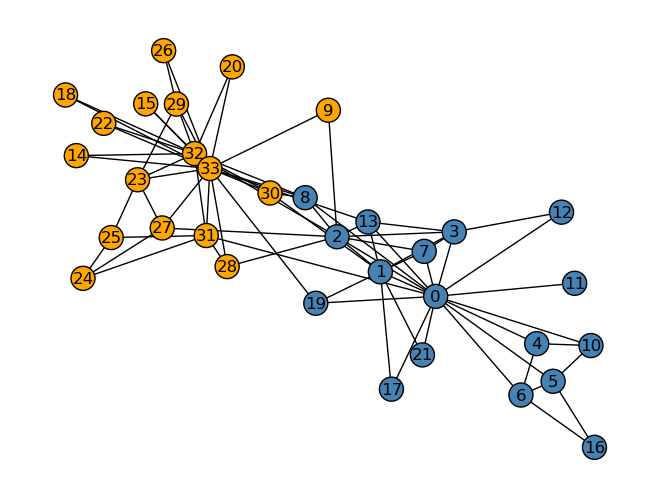
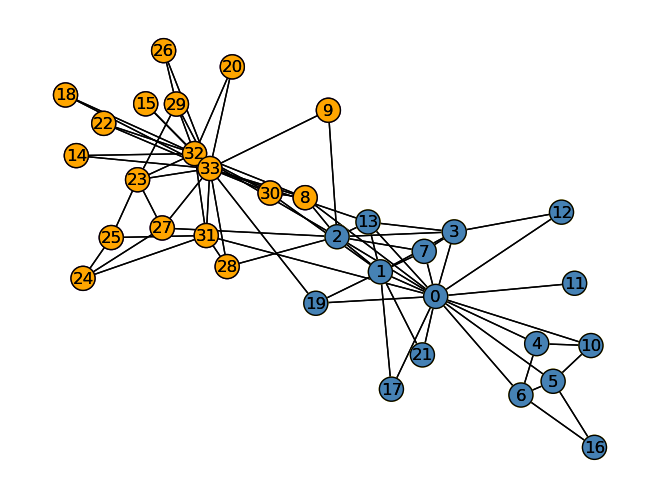
Now that we can calculate \(z\), let’s predict the group seperation in the Karate club and illustrate the preiction.
z_ = spectral_clustering(G) >0plot_graph(G, z=z_)nx.draw(G, layout, with_labels=True, node_color = ["steelblue"if z_[i] ==1else"orange"for i in G.nodes()], edgecolors ="black" )
The predicted labels from our unsupervised learning process are fairly accurate to the actual divisions in the Karate club. Only node 8 is mislabelled so the unsupervised learning implemented seems to be quite a successful example of using spectral clustering.